

oneM2M Overview
The oneM2M Global Organization creates Technical Specifications (TSs) to ensure that Machine-to-Machine (M2M) Communications can effectively operate on a Worldwide scale.
Seven (7) of the World's leading Information and Communications Technology (ICT) Standards Development Organizations (SDOs) launched in July 2012 a new Global Organization to ensure the most efficient Deployment of Machine-to-Machine (M2M) Communications Systems.
The new organization, called oneM2M, develops specifications to ensure the Global Functionality of M2M—allowing a range of Industries to effectively take advantage of the benefits of this emerging Technology.
The seven (7) majors ICT SDO founders of oneM2M are:

- The European Telecommunications Standards Institute (ETSI) , Europe
- The Association of Radio Industries and Businesses (ARIB), Japan
- The Telecommunication Technology Committee (TTC), Japan
- The Alliance for Telecommunications Industry Solutions (ATIS), USA
- The Telecommunications Industry Association (TIA), USA
- The China Communications Standards Association (CCSA), China
- The Telecommunications Technology Association (TTA), Korea
The members of the organization are devoted to developing Technical Specifications and Reports to ensure M2M Devices can successfully communicate on a Global scale.
The oneM2M Standardization work is split in five (5) WG:
- WG1: Requirements
- WG2: Architecture
- WG3: Protocols
- WG4: Security
- WG5: Requirements and Domain Models (former MAS-Management, Abstraction and Semantics)
The Test Specifications cover different testing aspects such as interoperability, interworking, Conformance, Performance and Security for different Protocols and Network elements.
Akraino IoT oneM2M Contact Person
Akraino oneM2M Contact person - Ike Alisson
oneM2M supported IoT Use Cases (UCs) - SAREF (Smart Applications REFerence) Ontology
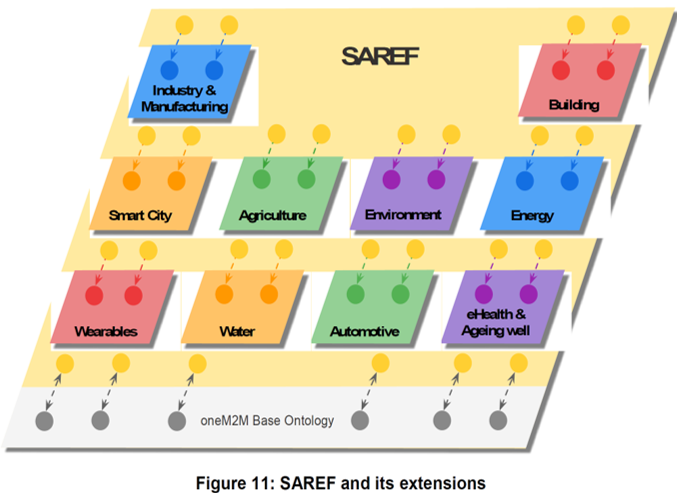
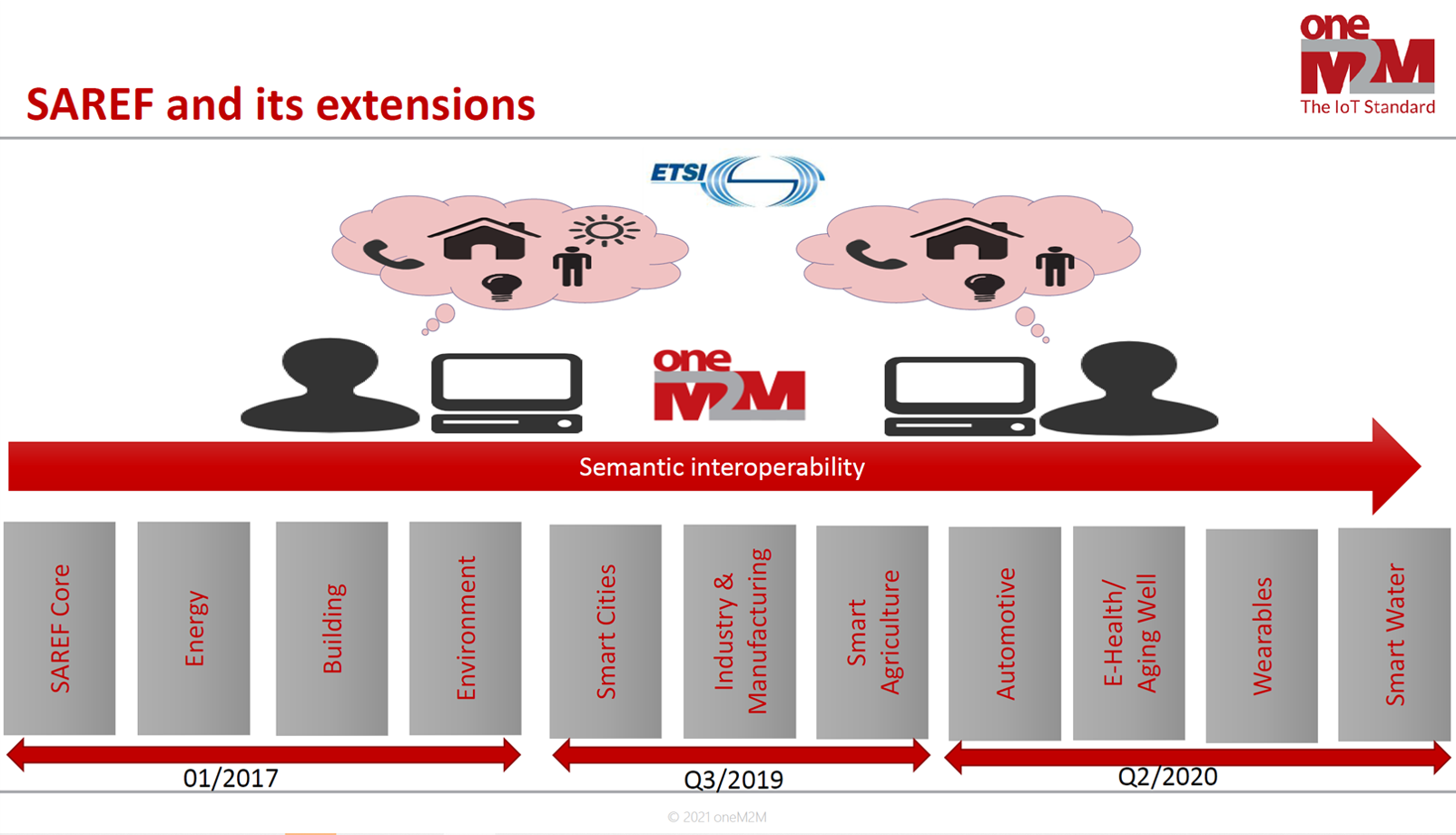
oneM2M supports IoT Use Cases (UCs) Smart M2M SAREF (Smart Appliances REFerence) Ontology. Initially, SAREF V1 was common to three (3) Domains, namely:
- Energy,
- Environment
- Buildings
The first core of SAREF (mapped into three (3) Applications’ Domains) has been improved to SAREF V2, thento SAREF V3 to enable mapping of SAREF with more Smart Applications domains such as:
- Smart City,
- Smart Industry and Manufacturing,
- Smart Agri-Food,
- Automotive,
- eHealth and Ageing-Well,
- Wearables,
- Smart Water,
- Smart Lift…)
Like this SAREF became Smart Applications REFerence Ontology (core SAREF) with its domain mapping extensions.
oneM2M Release Roadmap


oneM2M Layered Architecure Model
oneM2M Layered Model comprises three (3) layers:
- the Application Layer,
- the Common Services Layer
- the underlying Network Services Layer.
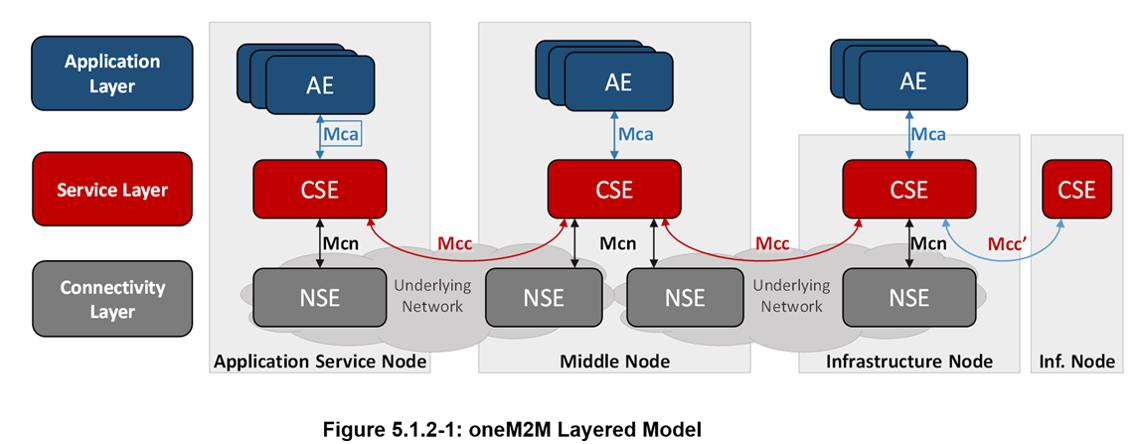
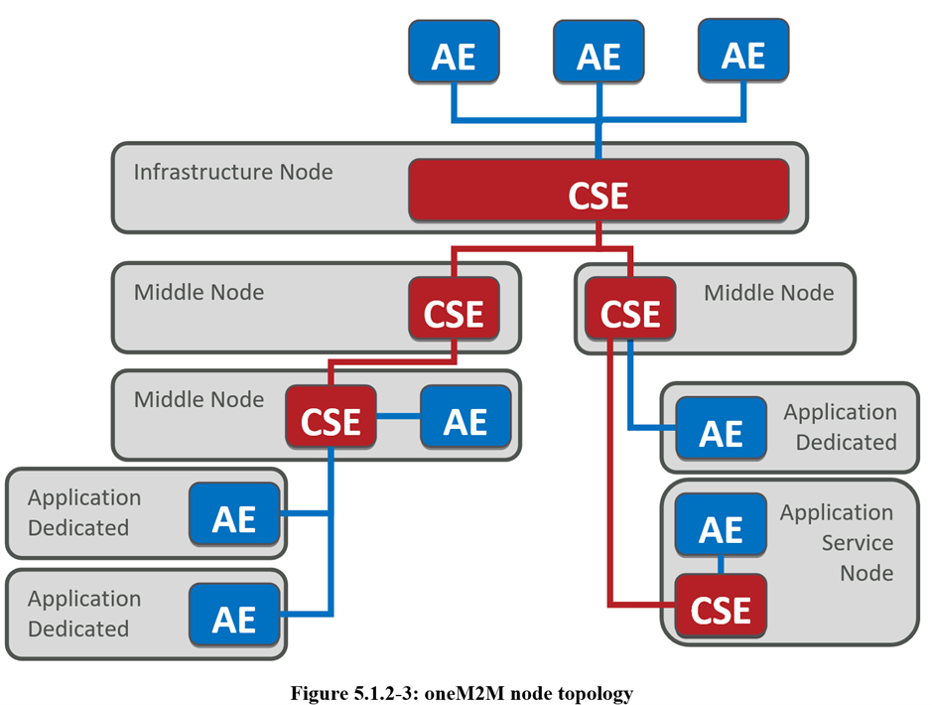
Application Entity (AE): The Application Entity is an Entity in the Application Layer that implements an M2M Application Service Logic. Each Application Service Logic can be resident in a number of M2M Nodes and/or more than once on a Single M2M Node. Each execution instance of an Application Service Logic is termed an "Application Entity" (AE) and is identified with a unique AE-ID.
Examples of the AEs include an instance of a fleet tracking application, a remote blood sugar measuring application, a power metering application or a pump controlling application.
Common Services Entity (CSE): A Common Services Entity represents an Instantiation of a Set of "Common Service Functions" of the oneM2M Service Layer. A CSE is actually the Entity that contains the collection of oneM2M-specified Common Service Functions that AEs are able to use. Such Service Functions are exposed to other Entities through the Mca (exposure to AEs) and Mcc (exposure to other CSEs) Reference Points.
Reference Point Mcn is used for accessing services provided by the underlying Network Service Entities (NSE) such as waking up a sleeping device. Each CSE is identified with a unique CSE-ID.
Examples of service functions offered by the CSE include: data storage & sharing with access control and authorization, event detection and notification, group communication, scheduling of data exchanges, device management, and location services.
Network Services Entity (NSE): A Network Services Entity provides Services from the underlying Network to the CSEs.
oneM2M Common Service functions (CSFs) (applied to all IoT Domains: SAREF IoT UCs (Use Cases))
oneM2M's horizontal Architecture provides a Common Framework for IoT. oneM2M has identified a Set of Common Functionnalities, that are applicable to all the IoT Domains (SAREF). Think of these functions as a large Toolbox with special tools to solve a number of IoT problems across many different domains. Very much like a screw driver can be used to fasten screws in a car as well as in a plane, the oneM2M CSFs are applicable to different IoT Use Cases (UCs)/Domains in different Industry Domains.
In its first phase, oneM2M went through a large number of IoT Use Cases (UCs) and identified a Set of Common Requirements which resulted in the Design of this Set of Tools termed Common Service Functions (CSFs).
Furthermore, oneM2M has standardized how these Functions are being executed, i.e. is has defined uniform APIs to access these functions. Figure 5.3.1-1 shows a grouping of these functions into a few different scopes.
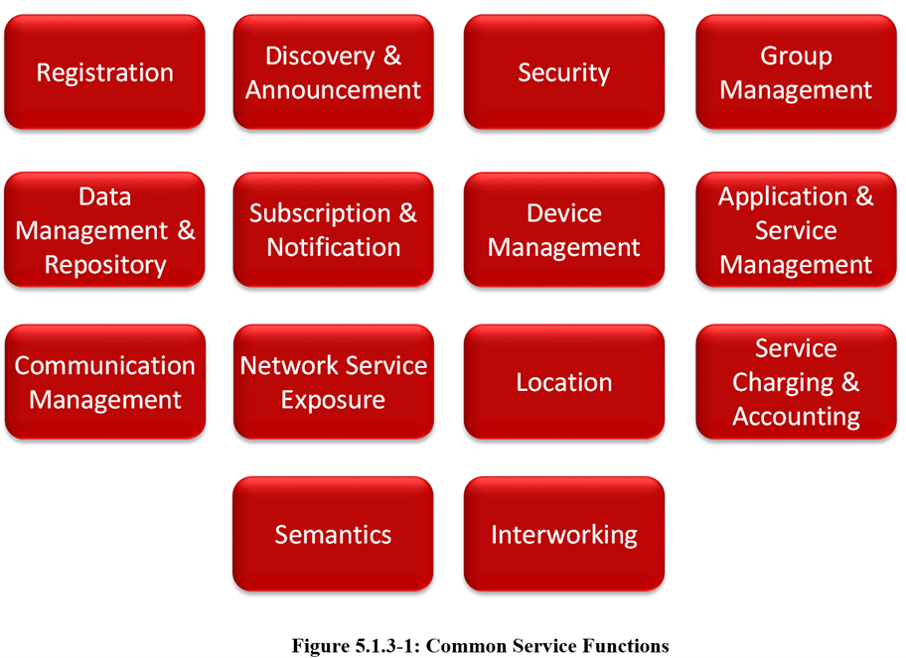

The Services above reside within a CSE (Common Service Entity) and are referred to as Common Services Functions (CSFs). The CSFs provide Services to the AEs via the Mca Reference Point and to other CSEs via the Mcc Reference Point.
oneM2M pre-integrated with 5G (3GPP) Specifications for cIoT
oneM2M baseline Architecture supports interworking with 3GPP and 3GPP Cellular Internet of Things (CIoT) Features such as IP and non-IP Data Control Plane Data Delivery. The oneM2M system may leverage the IoT related Features and Services that 3GPP added in Releases 10 through 15. Features and Services may be accessed by an ADN-AE, MN-CSE, or an ASN-CSE that is hosted on a UE and an IN-CSE that is able to access services that are exposed by a MNO.
The “3GPP Trust Domain” in Figure 5.2-1 captures the Functional entities that shall be part of the 3GPP Domain (the Network). Although the Figure 5.2-1 shows that the IN-CSE and IN-AE are outside of the 3GPP Domain, the IN-CSE may be part of the Operator domain (Fig. 4.2-1b).
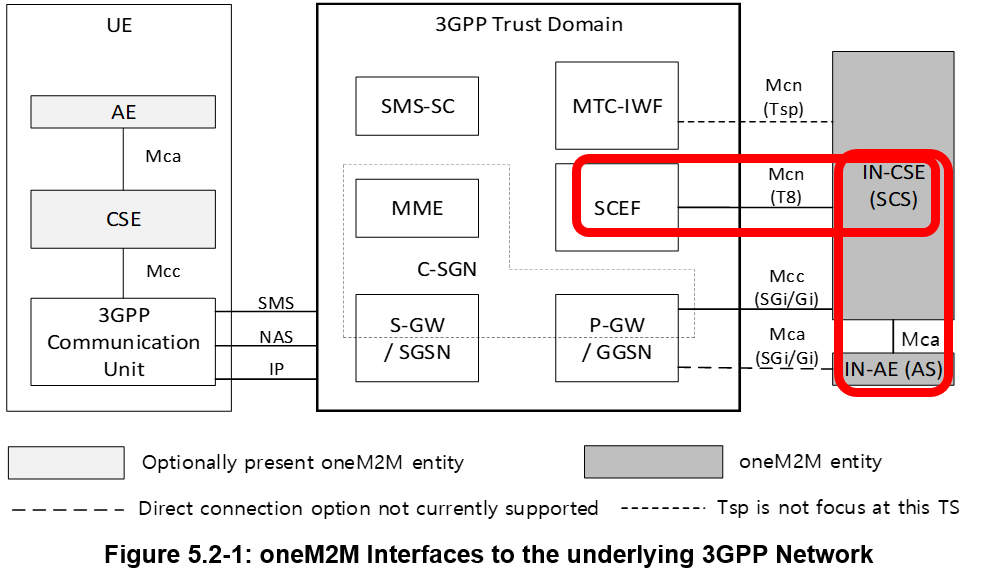
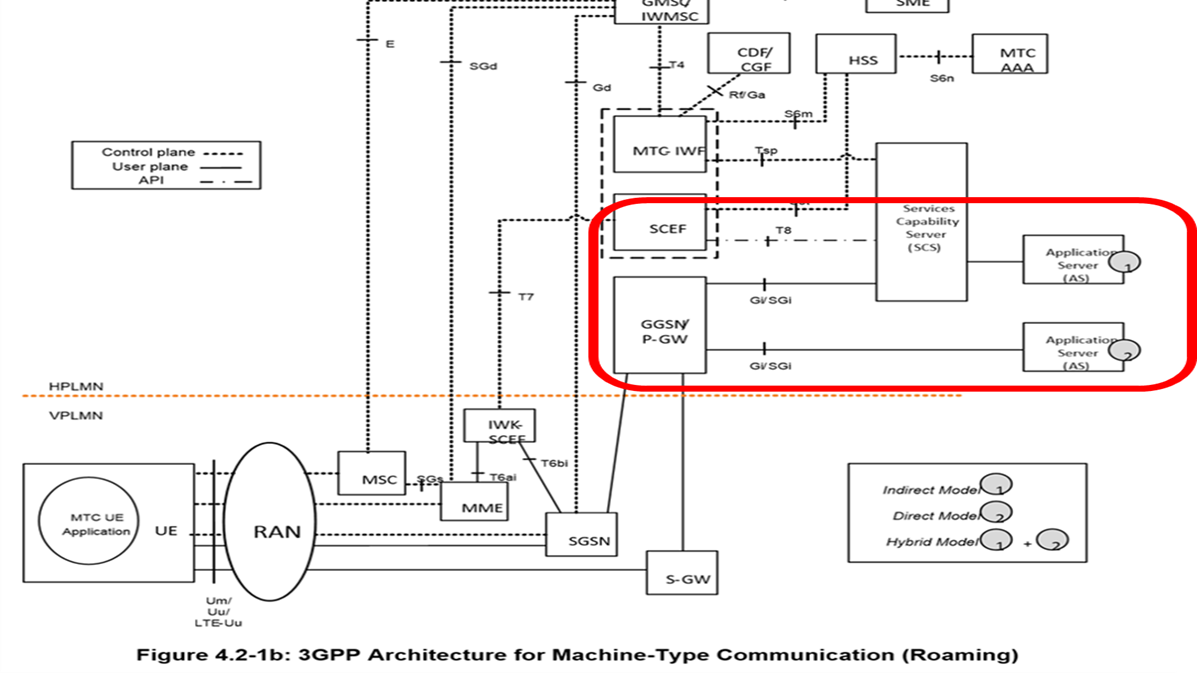
The 3GPP Trust Domain provides three (3) Interfaces to SCS/CSE (Service Capability Server/Common Service Entity) for MTC:
i) IP based interface at SGi reference point,
ii) RESTful API interface at T8 Reference Point,
iii) Diameter based interface at Tsp Reference Point.
The Service Capability Server (SCS) is a 3GPP term that refers to an entity which connects to the 3GPP Trust Domain to communicate with UEs used for Machine Type Communication (MTC).
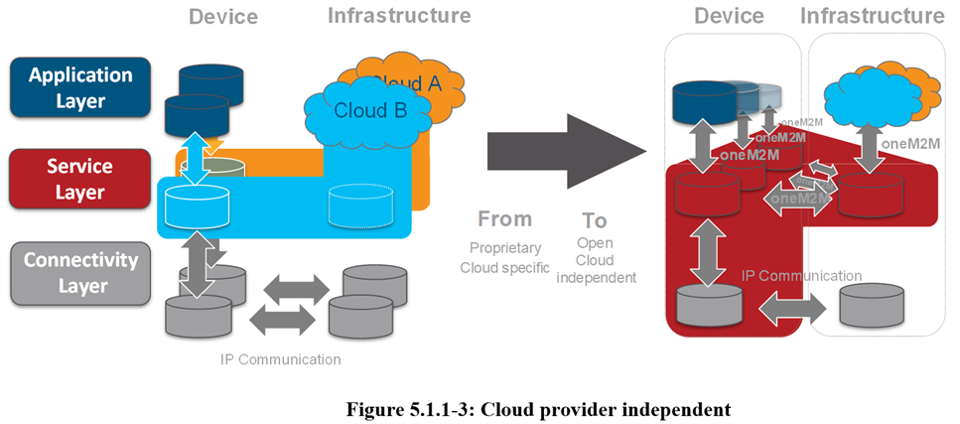
oneM2M Cloud Vendor Independent
oneM2M is Cloud Provider independent: From Fragmentation to Standards and decoupling Device, Cloud, and Application by Open Interfaces.
oneM2M addresses Edge/Fog computing in a deployment where the T8 Interface is exposed to the IN-CSE, therefore there is a “loose coupling” between the Edge/Fog Node and the Underlying Network.
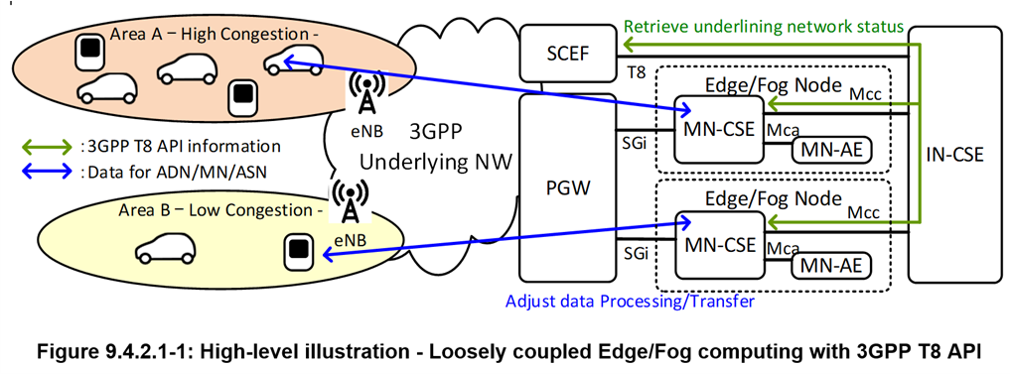
In some Edge/Fog scenarios, an oneM2M Edge/Fog Node can exchange with the 3GPP Underlying Network parameters to be used for optimizing the Data Traffic over the Underlying Network for a set of Field Domain Nodes hosted on UEs. As a result, oneM2M System can avoid the need for the IN-CSE to process Data for the Field Domain Nodes. Figure 9.4.2.1‑1 illustrates the high-level illustration for the loosely coupled Edge/Fog Computing with 3GPP T8 API. The Edge/Fog Node retrieves underlining Network information in a particular area from a SCEF via the IN-CSE and adjusts Data processing/transfer for the Field Domain Nodes.
Artificial Intelligence (AI) and oneM2M IoT Architectures
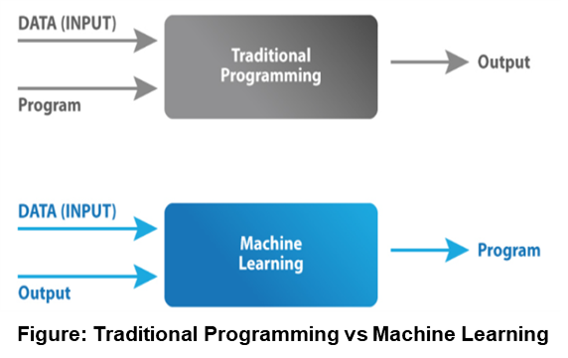
In Traditional Programming, the Input Data and a Program are fed into a Machine to generate Output. When it comes to Machine Learning (ML), Input Data and Expected Output are fed into the Machine during the Learning Phase, and it works out a Program for itself. To understand this better, refer to the Figure below:
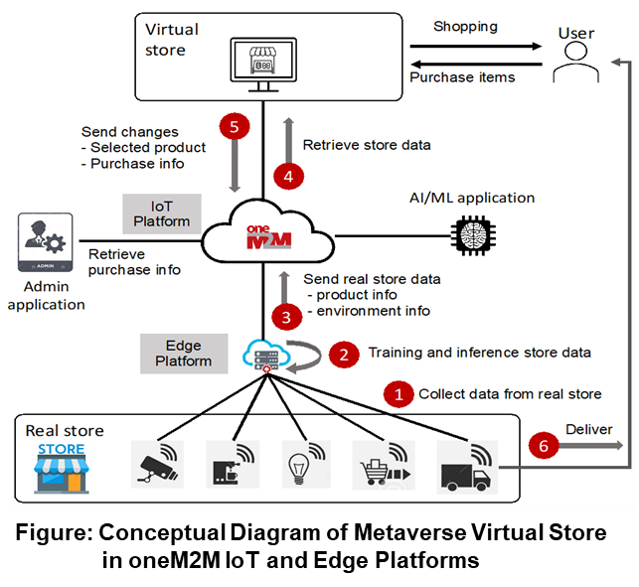
The word "Metaverse" is made up of the prefix "Meta" (meaning "beyond") and the stem "verse" (a back-formation from "universe"); the term is typically used to describe the Concept of a Future Iteration of the Internet, made up of persistent, shared, 3D virtual spaces linked into a perceived virtual universe. The Metaverse in a broader concept refer to realize Virtual Worlds using IoT, AI and Augmented Reality(AR)/Virtual Reality(VR).
A Metaverse-based Online Store where Stores in the real world are created as Digital Twins in the Metaverse Virtual Space, and Users visit a Virtual Store in the Metaverse Space to purchase preferred products. For Real-Time Synchronization between the Real-World and the Virtual Stores in the Metaverse, various Smart Sensors are used to sense Real-World Products intelligently.
The Edge Node at the Real World store loads a trained AI/ML Model and infers Products' information. The retrieved product Data is then transferred to the IoT Platform for Real-Time Synchronization.
A User can now purchase Products from a Virtual Store in the Meteaverse. The purchase info in the Metaverse is notified to the Administrator and the purchased product is delivered to the user.
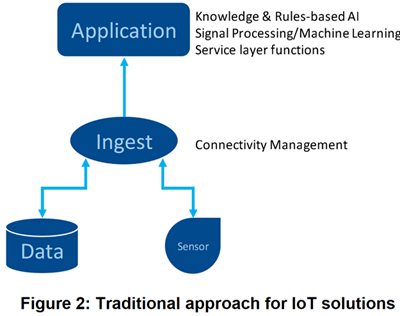
The flow of Data has an important bearing on Architectural Components for IoT Solutions, that is part of the analysis of the impact of AI on IoT Architectures, in particular the oneM2M Service Layer. The typical focus is on Data that leads to some form of decision being taken and is classified as 'User-Plane' (UP) Data. The basic Model for IoT Solutions begins with sourcing Data from IoT Devices (illustrated in left-hand side of Figure 1 below). This Data then passes through a Signal Processing and Machine Learning (ML) Process to extract key features and to represent them as Knowledge-based Objects. The next stage of processing involves the Application of Rules-based AI in areas related to Reasoning, Decision making, Supervision and Explainable AI.

This workflow illustrates some of the Generic and Commonly used Data Sourcing and AI/ML Capabilities involved in supporting End-to-End (E2E) IoT Solutions. It also shows how AI/ML Capabilities depend on Service Layer Capabilities. An example (illustrated in right-hand side of Fig. 1) is the relationship between a Registration Capability that manages the Identify of a Device and its Value in providing information about the Provenance of Data used in Pattern Recognition or Causal Inferencing Functions. In this example, the act of tracking data provenance depends on a 'Registration' Service Capability. Provenance tracking can improve the quality and dependability of an AI/ML system and occurs in the background to 'User Plane' (UP) activity. In Architectural terms, such background processes and use of Data that improve the Quality of AI/ML Applications occur in what is referred to as the 'Control Plane' (CP).
A traditional approach (illustrated in Fig 2 below) relies on an Application Ingesting and Storing Data for Processing. The SW implementation concentrates AI/ML and Service Layer Capabilities in the Application Layer. This places a burden on Solution Developers to master Application, AI and Service Layer disciplines.
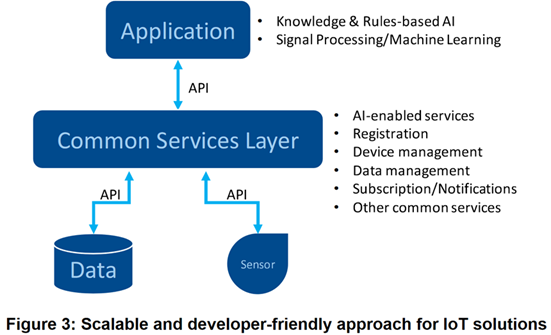
The alternative is a Developer friendly Approach (illustrated in Fig 3 below). This approach provides developers with an Abstraction Layer - i.e. a Common Service Layer - that makes AI and the more usual IoT-enabling Services accessible through a Standardized API. This arrangement means that the IoT Application can rely on notifications from the Common Services Layer to trigger its Functions when notified of changes in IoT Data. It can also draw on a Library of AI-enabled Services provided within the Common Services Layer.
A Three-Tier Frramework to organize the logical aspects of AI in IoT maps AI Applications into a 'User' Plane (UP).
oneM2M and CIM NGSI-LD (Context Information Management Next Generation Service Interface - Linked Data)
The Goal of the ETSI CIM ISG on Context Information Management is to issue TSs to enable multiple Organisations to develop interoperable SW implementations of a cross-cutting Context Information Management (CIM) Layer.
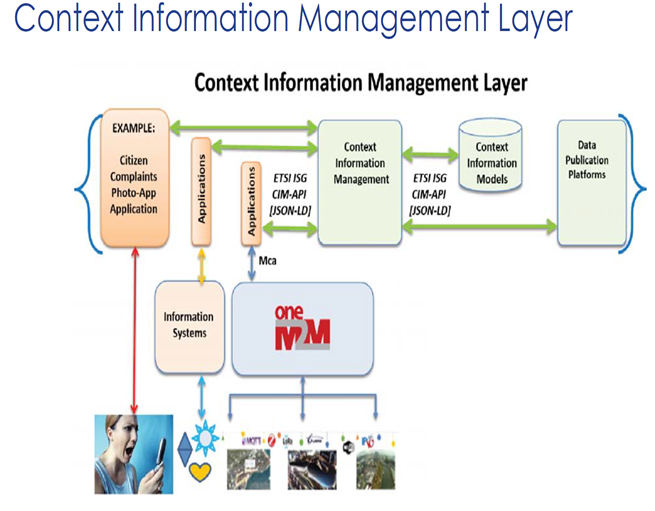
The CIM Layer should enable Applications to Discover, Access, Update and Manage Context information from many different sources, as well as publish it through interoperable Data Publication Platforms.
Phase 1 - detect and describe the Standardization Gaps.
Phase 2 - Developing ISG CIM Group Specifications in Phase 2 will subsequently fill these gaps. It is expected that an extension of the RESTful binding of the OMA NGSI API involving expression using JSON-LD could aid interoperability, so this and potentially other extensions will be considered.
The CIM API allows Users to Provide, Consume and Subscribe to Context Information close to Real-time Access to Information coming from many different Sources (not only IoT Data Sources).
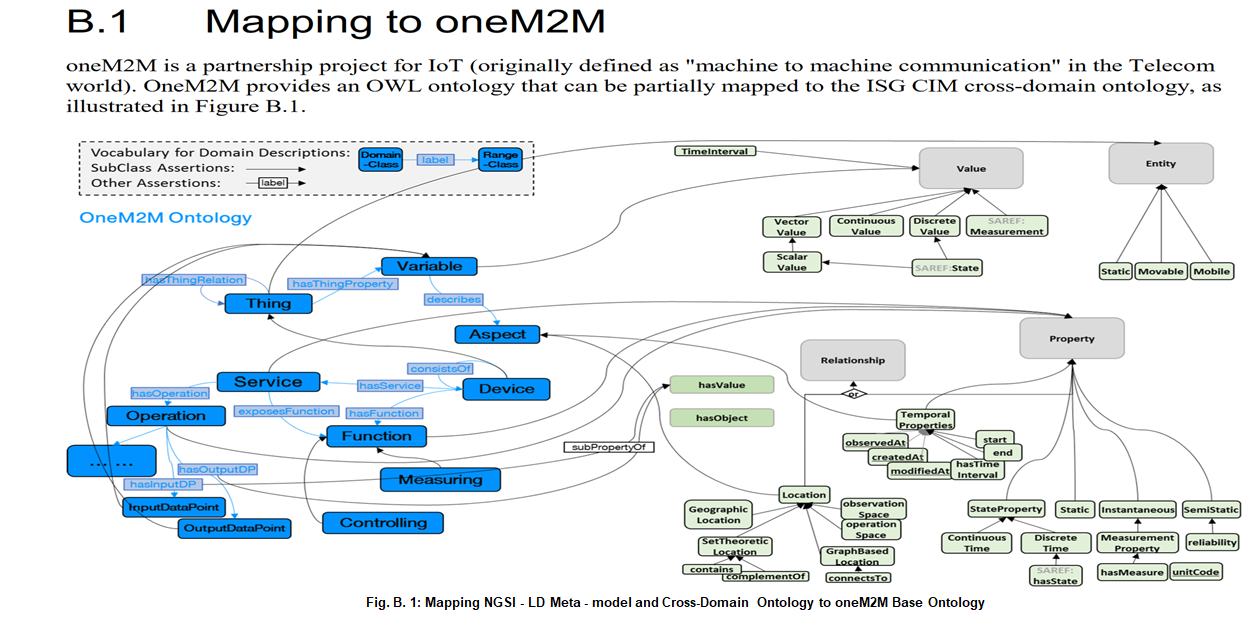
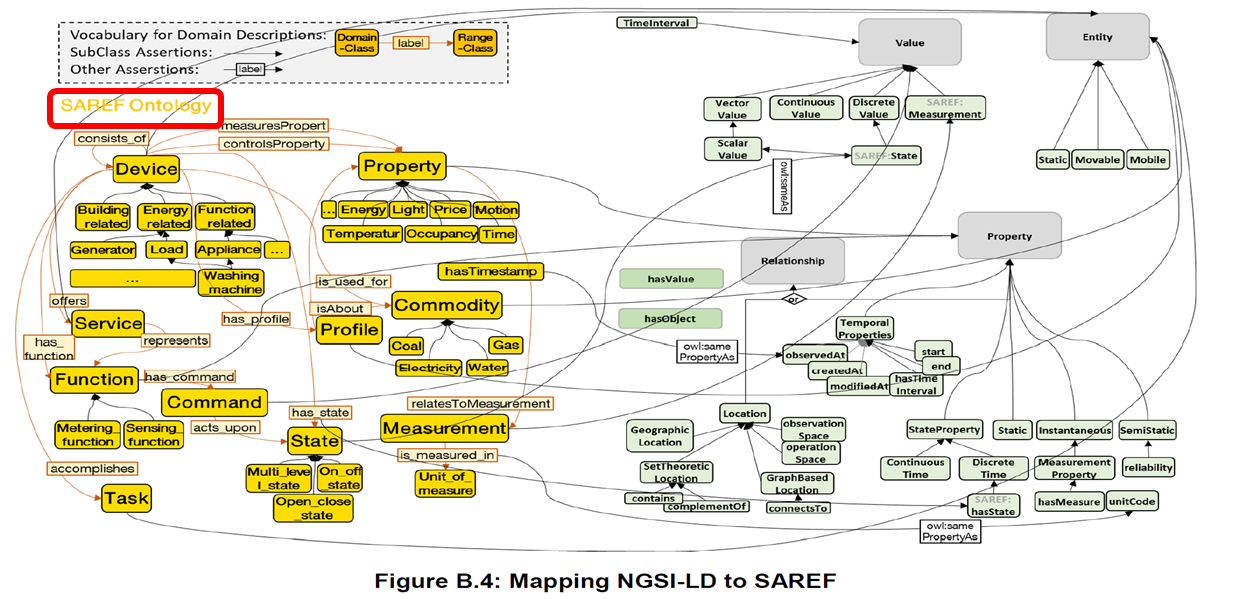
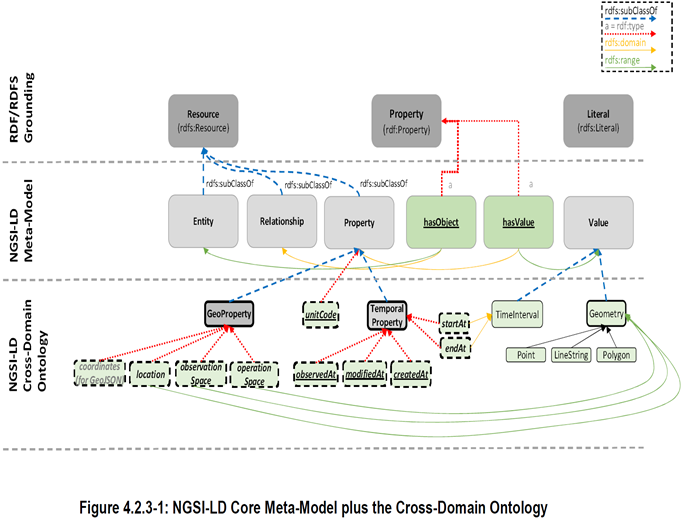
Core NGSI-LD @context
NGSI-LD serialization is based on JSON-LD , a JSON-based format to serialize Linked Data. The @context in JSON-LD is used to expand terms, provided as short hand strings, to concepts, specified as URIs, and vice versa, to compact URIs into terms. The Core NGSI-LD (JSON-LD) @context is defined as a JSON-LD @context which
contains:
- The core terms needed to uniquely represent the key concepts defined by the NGSI-LD Information Model, as mandated by clause 4.2.
- The terms needed to uniquely represent all the members that define the API-related Data Types, as mandated by clauses 5.2 and 5.3.
- A fallback @vocab rule to expand or compact user-defined terms to a default URI, in case there is no other possible expansion or compaction as per the current @context.
- The core NGSI-LD @context defines the term "id", which is mapped to "@id", and term "type", which is mapped to "@type". Since @id and @type are what is typically used in JSON-LD, they may also be used in NGSI-LD requests instead of "id" and "type" respectively, wherever this is applicable. In NGSI-LD responses, only "id" and "type" shall be used.
NGSI-LD compliant implementations shall support such Core @context, which shall be implicitly present when processing or generating context information. Furthermore, the Core @context is protected and shall remain immutable and invariant during expansion or compaction of terms. Therefore, and as per the JSON-LD processing rules [2], when processing NGSI-LD content, implementations shall consider the Core @context as if it were in the last position of the @context array. Nonetheless, for the sake of compatibility and cleanness, data providers should generate JSON-LD content that conveys the Core @context in the last position.
For the avoidance of doubt, when rendering NGSI-LD Elements, the Core @context shall always be treated as if it had been originally placed in the last position, so that, if needed, upstream JSON-LD processors can properly expand as NGSI-LD or override the resulting JSON-LD documents provided by API implementations.
The NGSI-LD Core @context is publicly available at https://uri.etsi.org/ngsi-ld/v1/ngsi-ld-core-context-v1.3.jsonld and shall contain all the terms as mandated by Annex B.
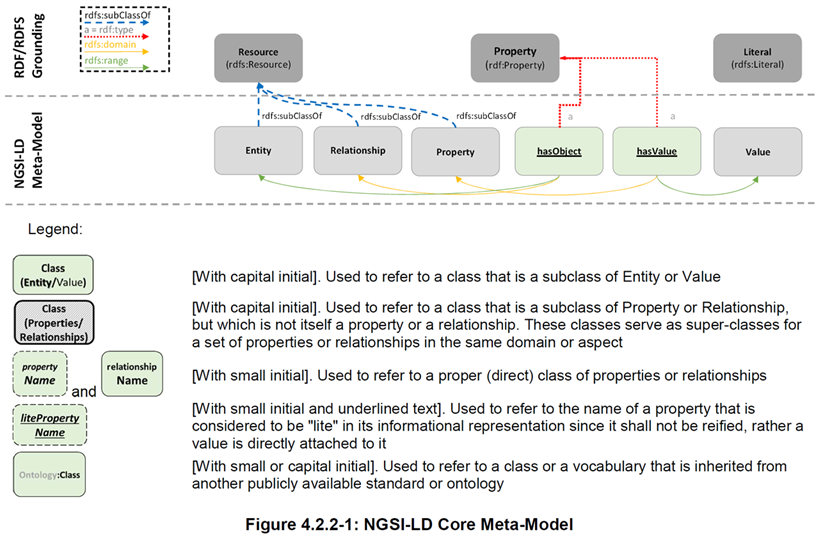
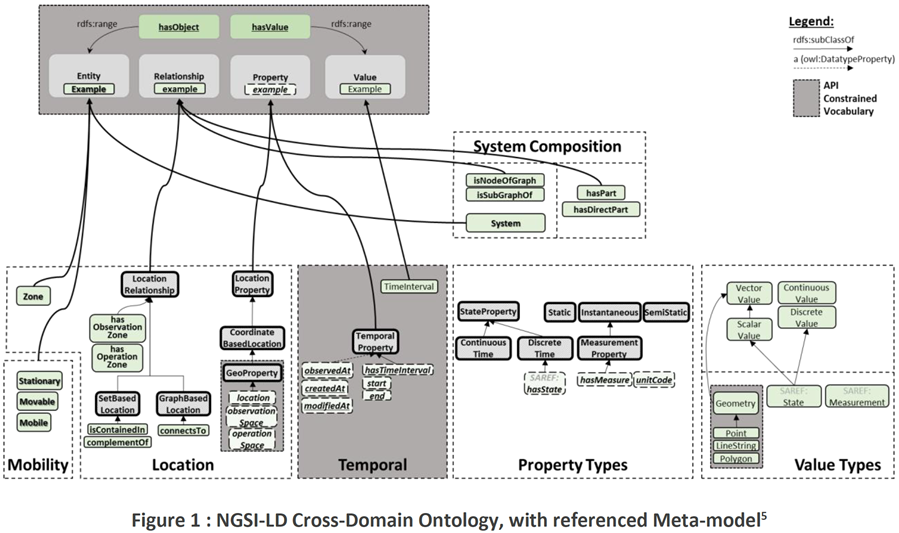
Using Typing vs. using Relationships or Propertiesin ETSI CIM NGSI-LD
Specific types, defined as subclasses of more generic classes, usually have additional properties or relationships that the superclass does not have, or have restrictions different from those of the superclass. There is, however, no single universal criterion to choose between those characteristics of entities that are best expressed by typing, and those that are best expressed by assigning properties.
Typing allows potential checking of data consistency (though full consistency cannot be enforced if external classes are used). Typing avoids replication of pieces of information across all instances of some category of entities that share similar characteristics, precisely because these characteristics may be referenced from the definition of the corresponding super-classes.
Any characteristic feature that is intrinsic to a category of entities, does not vary from one entity instance to another within this category, and may be used to differentiate this category from others, should be assigned to individual instances through typing.
All extrinsic and instance-dependent features should be defined as properties.
For example, the characteristic features of a room defined as a kitchen should set by its type inasmuch as they distinguish it from, say, a bathroom, in a generic way. Its area, and, even more obviously, its state (whether it is empty or occupied) should be defined as a per-instance properties, and whether it is adjacent to the living room should obviously be defined by a per-instance relationship.
Characteristics defined by continuous-valued numbers, or with many possible values such as colours, should be defined through properties and do not normally justify the creation of new classes, except when such a distinction is fundamental to the domain8.
Further modelling choices may be less obvious, for example whether it is useful to define subclasses of the generic kitchen class to e.g. distinguish between open-space vs. traditional kitchens.
It is usually better to use properties than to define sub-classes that might be too specific, too dependent on local cultures, or temporary trends.
In general, using a property with predefined values to capture this kind of subcategorization is not a good idea either (see the clause “Guidelines for Use of Properties” in the following). Yet if a distinction is key to our domain, sub-classing it may also be warranted. If a distinction is important in the domain and we think of the objects with different values for the distinction as different kinds of objects, then we should create a new class for the distinction. A stool would, in this view, not just be a chair with three legs, but a different category of seating furniture altogether. If distinctions within a class form a natural hierarchy, then we should also represent them as sub-classes. If a distinction within a class may be used in another domain (as a restriction, or with multiple typing), then it is also better to define it as a subclass than by using a property.
To summarize: instead of associating similar properties to different entities that belong to a common category, a class can be defined to associate all those attributes9 implicitly to all the instances that belong to it. In case of modification of a property, there would be one local placeholder to change, the attribute associated with the class, instead of changing the attribute in all the instances explicitly.
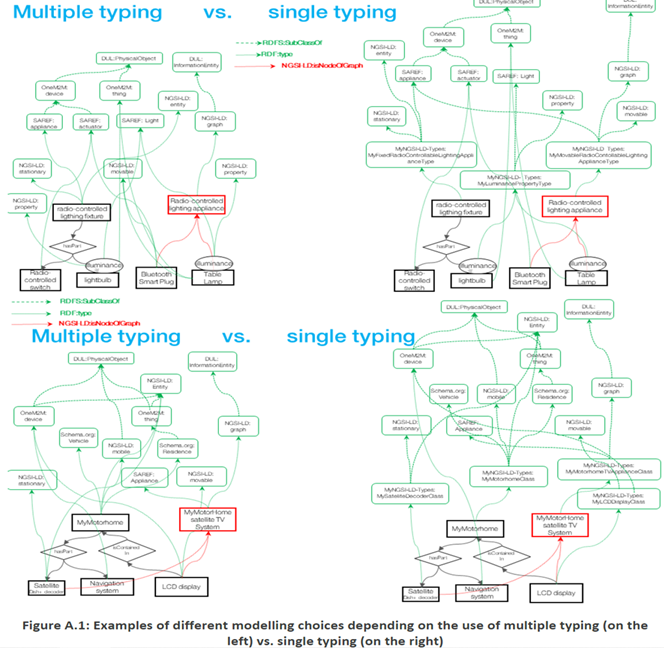
Recommendations for NGSI-LD Typing with Multiple Typing
The following recommendations apply if a form of multiple typing is supported in an NGSI-LD system (which means it does not use the AMPI) and they can be considered for future specifications of the NGSI-LD API.
Contrary to the case of single-typing, multiple typing alleviates the need to create specific "single-typing” classes that exactly match the requirements of the targeted domain and the entity instances to be modelled and may themselves inherit multiple classes from shared ontologies. Instead, with multiple typing, a similar result may be achieved by directly referencing these classes from the instances being categorized, thus picking and choosing known features from a variety of known ontologies, including the NGSI-LD cross-domain and metamodel ontologies. Choices could be made from many ontologies, thesauri, taxonomies, and vocabularies, be they generic or domain-specific, high-level, mid-level or low-level. Classes are not, in general, mutually exclusive, so multiple-typing avoids a granularity that amounts to define every single type by a small, mutually exclusive set of instances, cross-referencing multiple classes being a more versatile and adaptable way to describe their peculiarities than pigeonholing them into narrowly defined categories
With multiple-typing, new instances should be created by :
- referencing, directly or indirectly, at least one of the root classes of the NGSI-LD meta model (entity, relationship, property)
- referencing, directly or indirectly, generic classes from the NGSI-LD cross-domain ontology (for e.g. defining whether the instances being addressed are mobile, movable, or stationary). This is more generic than the use of more specific concepts as they might be defined in domain-specific ontologies.
- referencing multiple classes, chosen from generic or use-case-specific ontologies, to characterize specific features or peculiarities of these instances. With multiple typing, this is preferable to the use of properties or narrowly defined subcategories.
oneM2M Semantic enablement and ASD (Advanced Semantic Discovery) for (AE) "Resources"
The oneM2M Architectural Model in oneM2M Semantic enablement specification is based on the generic oneM2M Architecture for the Common Service Layer specified in oneM2M TS Functional Architecture.
The Core Functionality supporting Semantics resides at various CSEs, providing Services to the AEs via the Mca Reference Point and interacting with other CSEs via the Mcc Reference Point.
The Semantics (SEM) CSF (Common Service Function) is an oneM2M Common Service Function (CSF) which enables Semantic Information Management (SIM) and provides the related functionality based on this Semantic Information. The Functionality of this CSF is based on Semantic descriptions and implemented through the specialized resources and procedures described in oneM2M Semantic Enablement specification
The SEM CSF includes Specialized Functional Blocks such as: SPARQL Engine, Repositories for Ontologies and Semantic Descriptions, which may be implemented via Permanent or Temporary Semantic Graph Stores, etc.
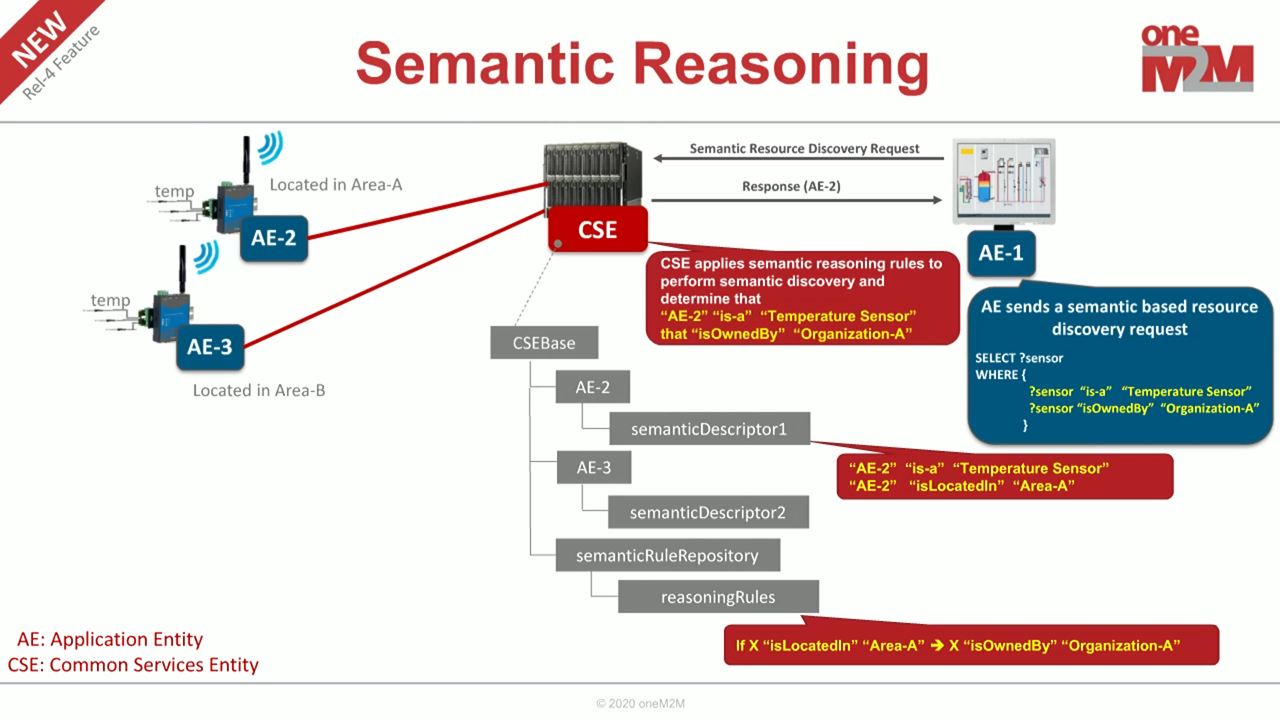


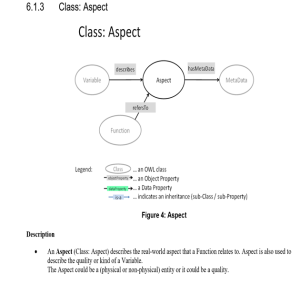
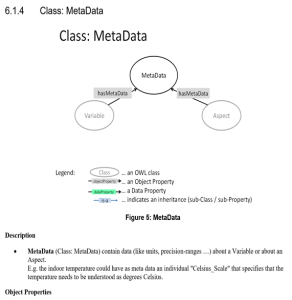
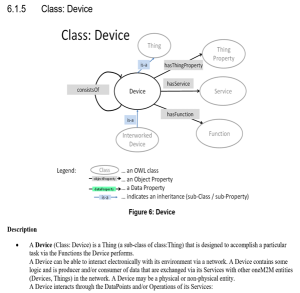
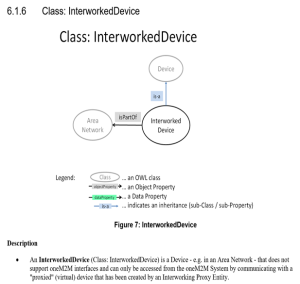
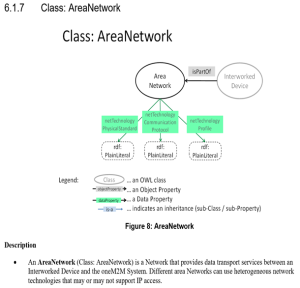
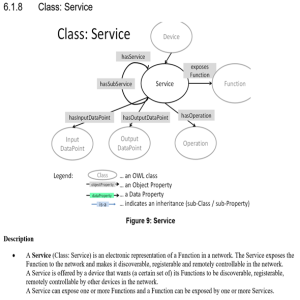
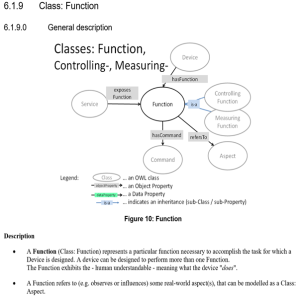
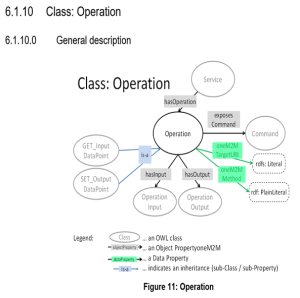

oneM2M Semantic enablement for (AEs) and ETSI Smart M2M Resource ASD (Advanced Semantic Discovery)
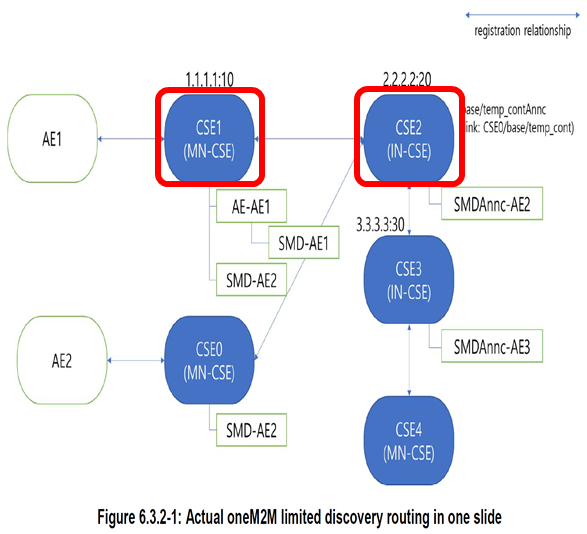
Semantic Discovery in presence of a "Network" of M2M Service Providers (M2MSPs)
The Advanced Semantic Discovery (ASD) aims to discover AEs (also called Resources) that are registered/announced to some CSEs.
The ASD could start from any AE, even these ones not belonging to the same Trusted Domain.
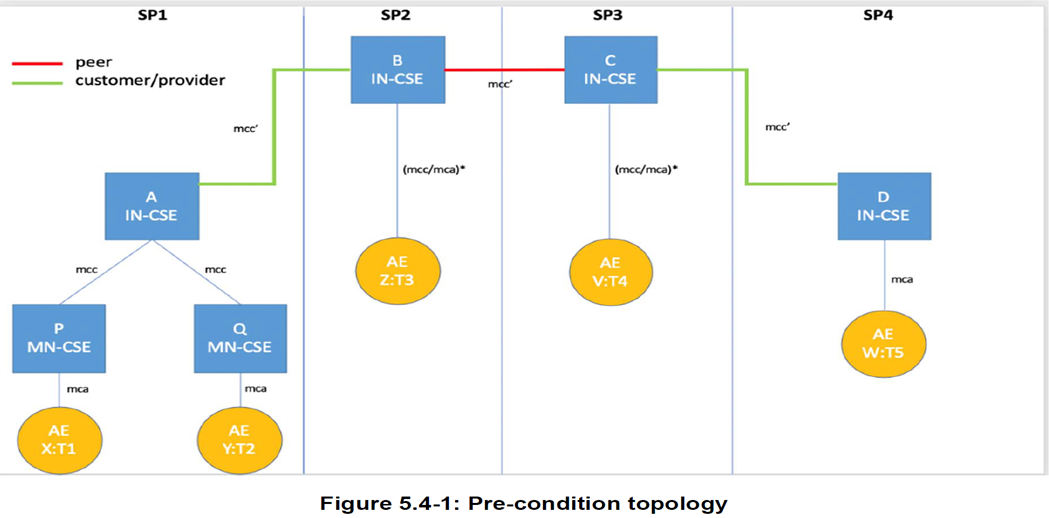
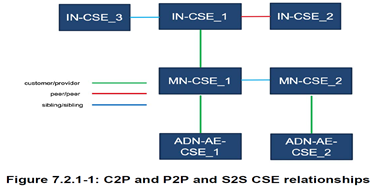
The ASD differs from the usual one present in oneM2M in the sense that one (or many) AE could be searched for even without knowing its identifier, but just knowing its TYPE or ONTOLOGY membership, as shown in Figure 6.3.1-1.
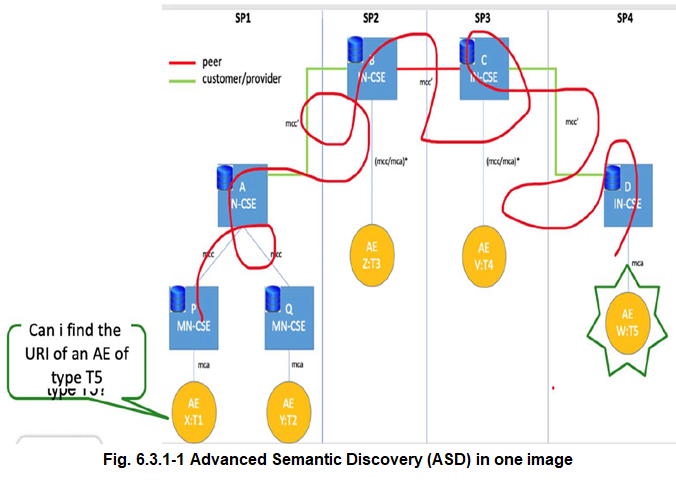
Advanced Semantic Discovery (ASD) in Figure 6.3.2-1 below describes oneM2M as Semantic Discovery involving multiple CSEs.
ASD within Distributed Network of CSEs belonging a single Service Provider & across different IoT Service Providers.
Example of SRT (Semantic Routing Table)

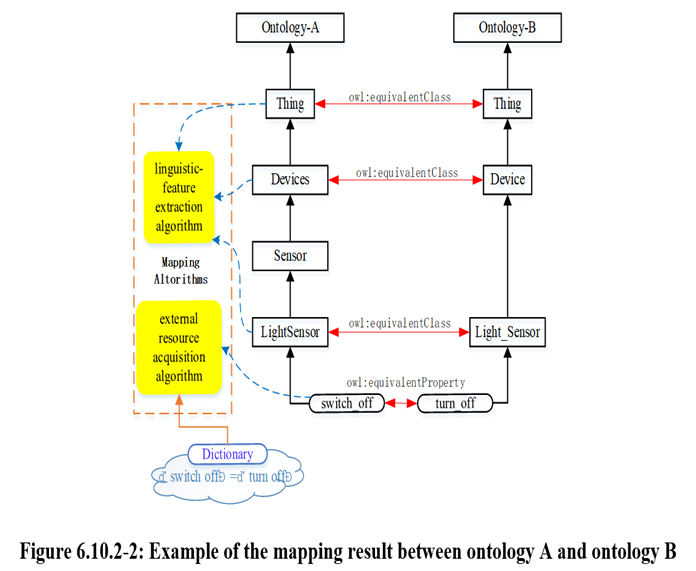
The Ontology Mapping Task performed by
=> Create Operation or
=> Update Operation against an <OntologyMapping> Resource on a Hosting CSE.
A Retrieve operation against the same <OntologyMapping> Resource shall be used to get the result of Ontology mapping. A Delete operation against a <OntologyMapping> Resource shall follow the basic procedure as specified.
3GPP 5G NDL (Network Data Layer) and oneM2M Semantic enablement and ETSI SmartM2M ASD integration
The information related to oneM2M Semantic enablement and ETSI SmartM2M ASD support (integration) with 3GPP specified 5G NDL (Network Data Layer in which Data "Compute" is separated from "Storage" in the process of virtualization of 5G NFs into VNFs/PNFs by separating the context in the NF's Application related Data from the Business Logic in the NF's Application related Data and stored separately in Nodes specified by 3GPP for 5G and denoted as "Structured" and "Unstructured" Data and supported in 5G 3GPP Rel 16 ATSSS (Access Traffic Steering, Switching and Splitting) is deliberately not included and part of the presentation on the oneM2M and 5G New Services.