...
Storidge is a highly available persistent storage for K8s with auto-failover & recovery. Storidge automates storage infrastructure as code, delivering a persistent storage platform for Docker Swarm and Kubernetes. Storidge’s software enables automated storage orchestration including provisioning, application performance, data consistency and data protection via software. Storidge’s storage orchestrator enables stress-free storage administration for modern DevOps workflows.
EdgeXFoundry EdgeX Foundry
EdgeXFoundry EdgeX Foundry is a Middleware for dual processing of data to/from edge devices. It takes the sensor input from the devices and delivers it to the applications over the network to the end-users. Edgex Foundry has the microservices packed as docker images. EdgeX can be installed using the docker-compose file or from the snap store in a Linux environment.
...
| Item | Capacity | ||||||
|---|---|---|---|---|---|---|---|
| Number of nodes | 3 | ||||||
| Node Size | t4g.medium - 2vCPUs - 4 GiB Memory | ||||||
Disks in Storidge HA Clustering mode
| 3 Disks per node - 100 GB each. | ||||||
| VPC | Pre-existing VPC | ||||||
| Subnet | Public (for now). Will switch to private subnet with Gateway configuration in future releases. | ||||||
| AMI | Ubuntu Server 18.04 LTS |
Automation
Terraform Automation
Terraform takes two input files to automate the infrastructure provisioning and produces a state file at the end of the automation.
- Variables file (variable.tf) - Input file : Run time tunables that helps to customize the infrastructure configuration. <TBD> - list of variables taken from the variable.tf file and the list of ENVs read.
- terraform configuration file (main.tf) - Input file : The Terraform configuration file contains the workflow and automation scripts to create the microk8s cluster.
- worker_user_data.tmpl - user data for the worker nodes : This file maintained by the blueprint internally to dynamically configure the join token on the worker nodes.
- terraform state file: Terraform maintains the current state of the infrastructure in the state file. The state file remains empty until the first terraform initialization. The stateful is used for further updates or tear down of the cluster.
Variables.tf file : The provider and the resource blocks in the main.tf file can be configured by changing the values in variables.tf file.
For example, if you want to change the aws_instace type from t2.small to t2.micro, set the TF_VAR with the appropriate values. Other resource-specific values like aws_region, aws_ami, vpc_id and the subnet can also be changed the same way by editing the respective TF_VAR environment variables.
AWS Infrastructure
The below graph shows the infrastructure resources and their dependencies while provisioning the stack using terraform.
...
Master and Worker nodes are provisioned in this order:
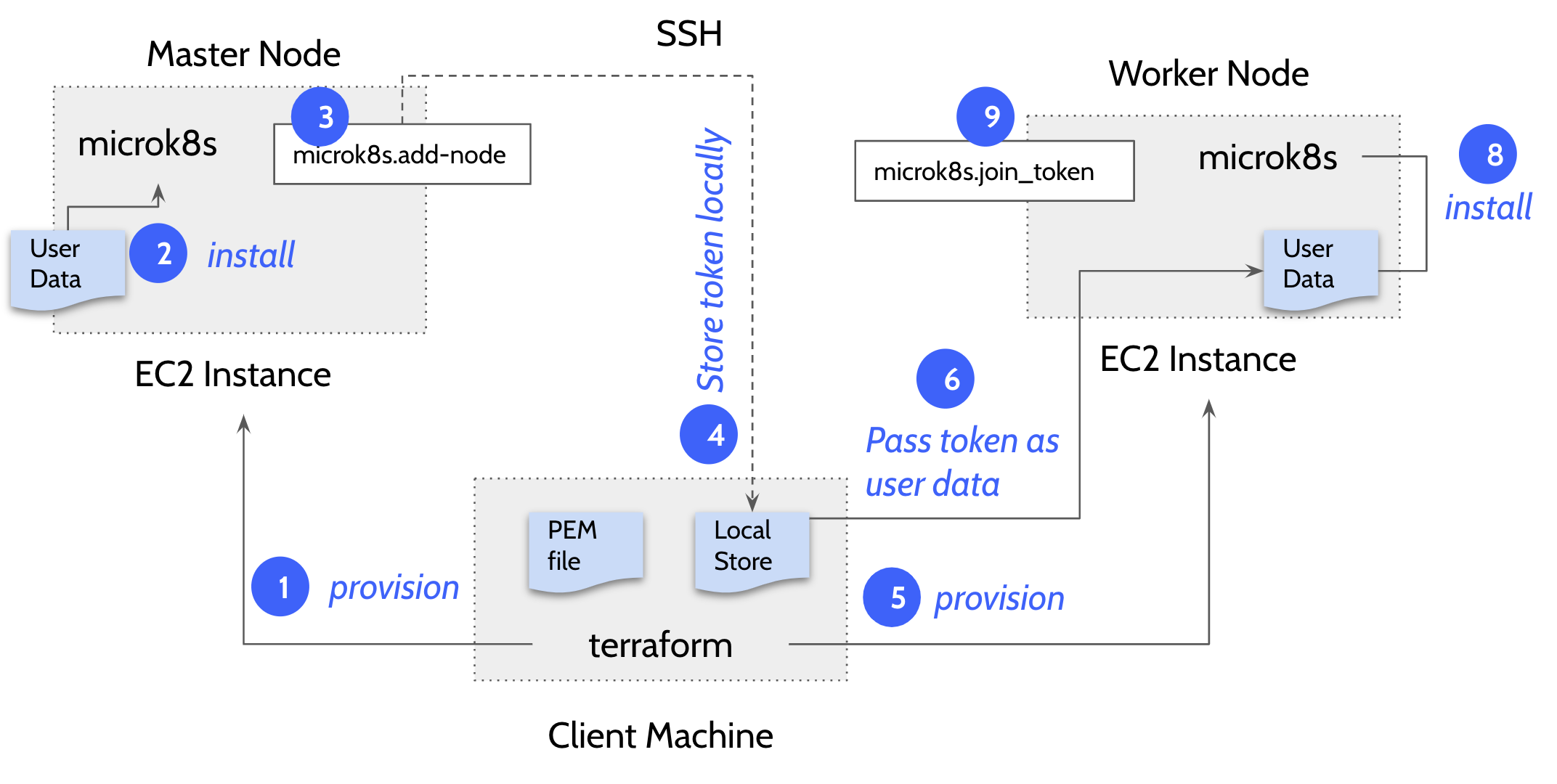
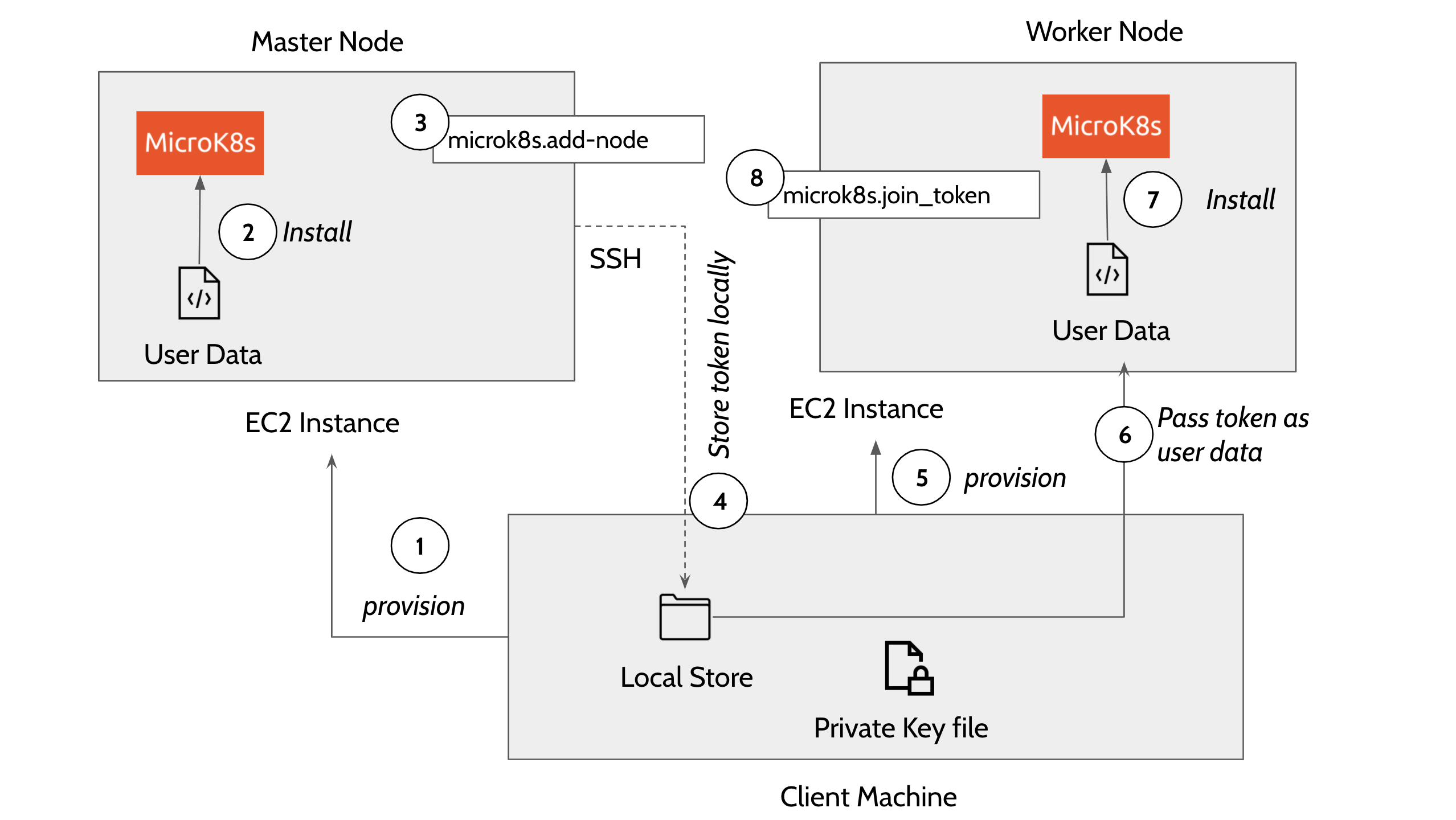
- Provision master node. The template executes EC2 user_data on the master node that uses snap package manager to install microk8s.
The user_data in the main.tf file installs the microk8s inside the EC2 instance.
Code Block language java #!/bin/bash sudo su apt update -y >> microk8s_install.log apt install snapd -y >> microk8s_install.log snap install core >> microk8s_install.log export PATH=$PATH:/snap/bin snap install microk8s --classic --channel=1.20/stable >> microk8s_install.log microk8s status --wait-ready microk8s enable dns >> microk8s_install.log microk8s add-node > microk8s.join_token microk8s config > configFile-master Once the microk8s master is installed on the first node, the template then does a remote SSH command to the master node and generates a token by executing the command - ‘microk8s.add-node’ This makes use of the
PEMprivate key file in the local directory to execute the remote SSH command. The token generated in this step is used to join the remaining nodes to the cluster. The following describes how a connection block is configured in main.tf file to perform a remote exec to the master node.
Code Block language java connection { host = self.public_ip type = "ssh" user = "ubuntu" password = "" private_key = "${file("terraform.pem")}" }
- Copy the generated token on the remote machine to the local machine using the terraform ‘datasource’ plugin.
- Now provision the worker nodes and install microk8s on the remaining nodes
Use the local datasource to read the join token and add the worker nodes to the master node using the command ''microk8s.join
<token>"_token". Following code block explains how a worker node is added to the cluster using remote exec.
Code Block language java provisioner "remote-exec" { inline = ["until [ -f /microk8s.join_token ]; do sleep 5; done; cat /microk8s.join_token"] }
| Info | |||||
|---|---|---|---|---|---|
| |||||
We create an 'ALLOW ALL' ingress and egress rule security group. In the future releases, this will be configured dynamically based on user inputs.
|